a game in which two players alternately put crosses and circles in one of the compartments of a square grid of nine spaces.
1、Play tic-tac-toe
2、Displayed when finalized
3、History is saved as the game progresses
4、Review the start history and refer to the previous state of the board
Runs the app in the development mode.
Open http://localhost:3000 to view it in the browser.
The page will reload if you make edits.
You will also see any lint errors in the console.
yarn test
Launches the test runner in the interactive watch mode.
See the section about running tests for more information.
yarn build
Builds the app for production to the build folder.
It correctly bundles React in production mode and optimizes the build for the best performance.
The build is minified and the filenames include the hashes.
Your app is ready to be deployed!
See the section about deployment for more information.
yarn eject
Note: this is a one-way operation. Once you eject, you can’t go back!
If you aren’t satisfied with the build tool and configuration choices, you can eject at any time. This command will remove the single build dependency from your project.
Instead, it will copy all the configuration files and the transitive dependencies (Webpack, Babel, ESLint, etc) right into your project so you have full control over them. All of the commands except eject will still work, but they will point to the copied scripts so you can tweak them. At this point you’re on your own.
You don’t have to ever use eject. The curated feature set is suitable for small and middle deployments, and you shouldn’t feel obligated to use this feature. However we understand that this tool wouldn’t be useful if you couldn’t customize it when you are ready for it.
This repository provides the official Tensorflow 2 implimentation of the illuminant estimation algorithm BoCF proposed in paper Bag of Color Features For Color Constancy accepted in IEEE Transactions on Image Processing (TIP) using INTEL-TAU dataset.
BoCF
In this paper, we propose a novel color constancy approach, called BoCF, building upon Bag-of-Features pooling. The proposed method substantially reduces the number of parameters needed for illumination estimation. At the same time, the proposed method is consistent with the color constancy assumption stating that global spatial information is not relevant for illumination estimation and local information (edges, etc.) is sufficient. Furthermore, BoCF is consistent with color constancy statistical approaches and can be interpreted as a learning-based generalization of many statistical approaches.
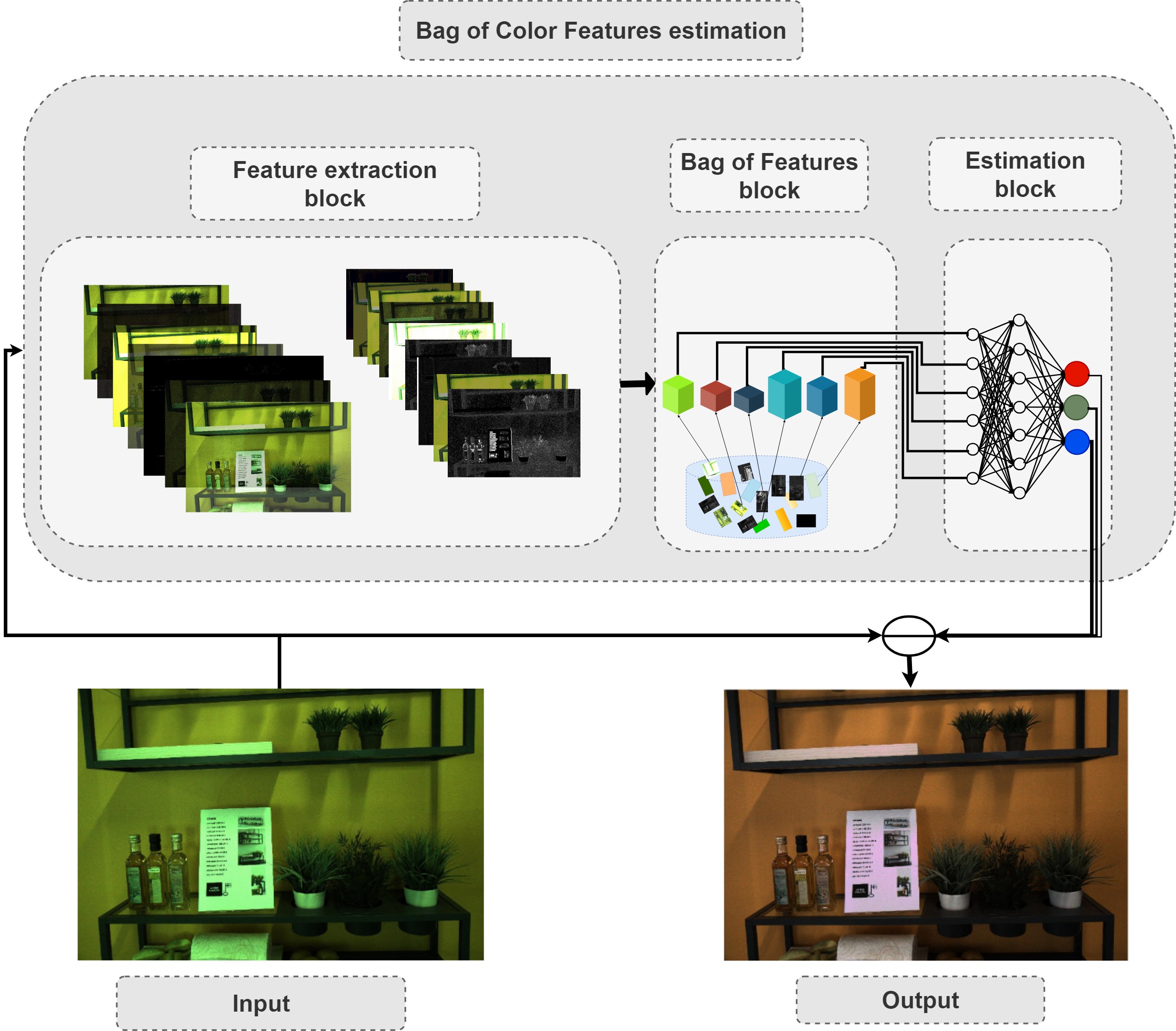
BoCF consists of three main blocks: feature extraction block, Bag of Features block, and an estimation block. In the first block, regular convolutional layers are used to extract relevant features. Inspired by the assumption that second order gradient information is sufficient to extract the illumination information, we use only two convolutional layers to extract the features. In the second block, i.e., the Bag of Features block, the network learns the dictionary over the non-linear transformation provided by the first block. This block outputs a histogram representation, which is fed to the last component, i.e., the estimation block, to regress to the scene illumination.
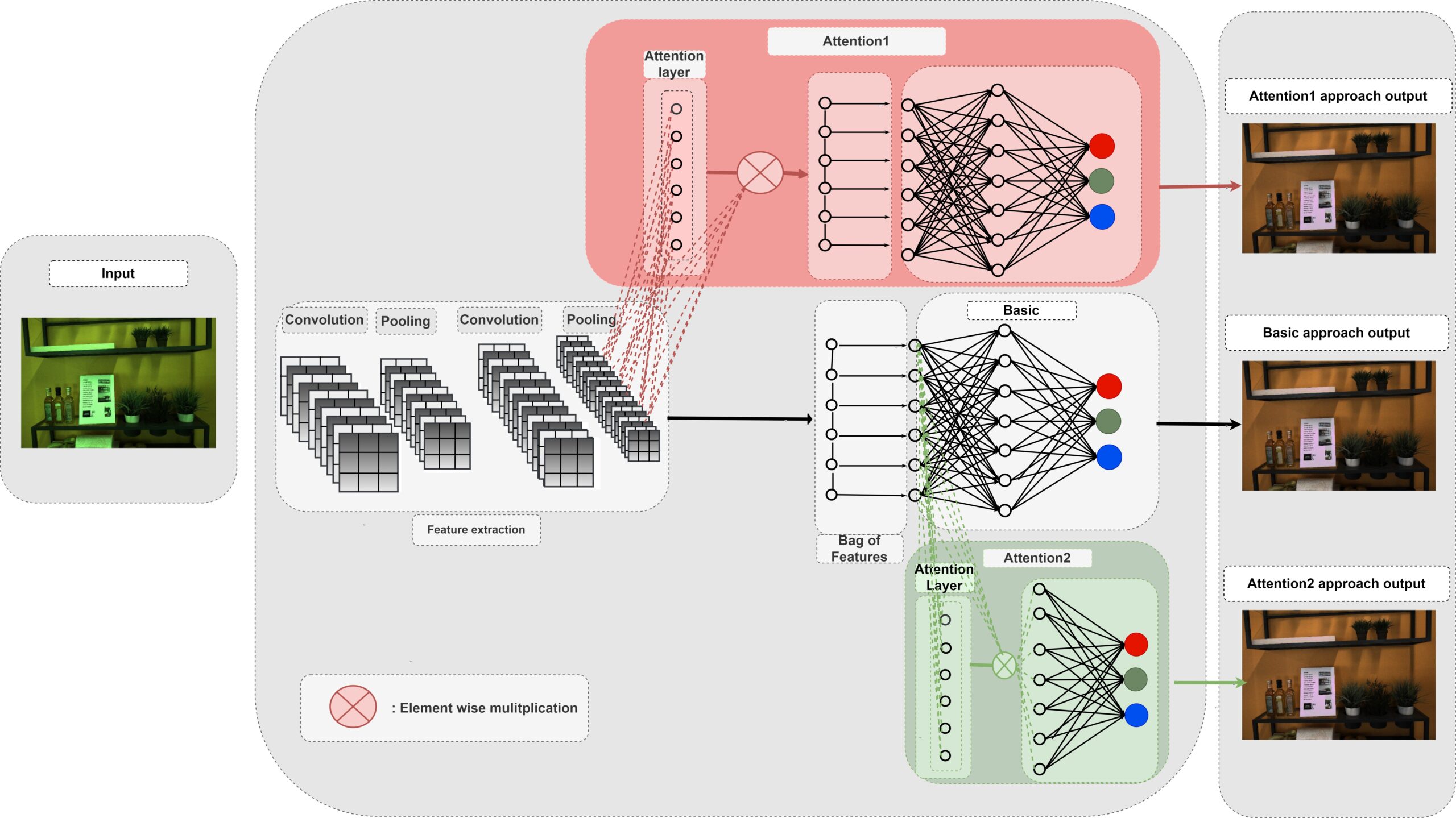
To further improve the illumination estimation accuracy, we propose a novel attention mechanism for the BoCF model with two variants based on self-attention. In the first variant (Attention1), we add an attention mechanism between the feature extraction block and the Bag of Features block. This mechanism allows the network to dynamically select parts of the image to use for estimating the illumination, while discarding the remaining parts. Thus, the network becomes robust to noise and irrelevant features. In the second variant (Attention2), we add an attention mechanism on top of the histogram representation, i.e., between the Bag of Features block and the estimation block. In this way, we allow the network to learn to adaptively select the elements of the histogram which best encode the illuminant information. The model looks over the whole histogram after the spatial information has been discarded and generates a proper representation according the current context (histogram).
Usage
INTEL-TAU Dataset
INTEL-TAU dataset is the largest publicly available illumination estimation dataset. It is composed of 7022 scenes in total. The variety of scenes captured using three different camera models, i.e., Canon 5DSR, Nikon D810, and Sony IMX135, makes the dataset appropriate for evaluating the camera and scene invariance of the different illumination estimation techniques.
Dependencies
The project was tested in Python 3. Run pip install -r requirements.txt to install dependent packages.
Using our codes.
1/ Download the preprossed 1080p TIFF variant of the dataset.
2/ Set the root path variable in main_BoCF.py to your data path, e.g., ‘root_path’: ‘/mnt/Data/Firas2/Intel_v3/processed_1080p’
3/ Run the script main_BoCF.py : python3 main_BoCF.py
Walking through the main code (main_BoCF.py):
1/ First a dataset class is created using the paramters
3/ We augment the training and validation data relative to the current fold and save the augmented dataset relative to the fild in the aug_path.
Note1: This step is only excuted in case the augmented dataset folder does not exist.
Note2: Don’t stop the code in the middle of this step. In case the code was stopped before this step is finished, the aug_path folder needs to be deleted manually.
4/ We create a BoCF model. There are two hyper-parameters: histogram_size (default=150) and attention_variant (default=2). If attention_variant needs to be changed to 1 to use attention1 variant or 0 to test the standard approach without attention.
model = BoCF(n_codewords = hist_size , show_summary= True,attention =attention_variant)
5/ Training the model and testing it using the test set
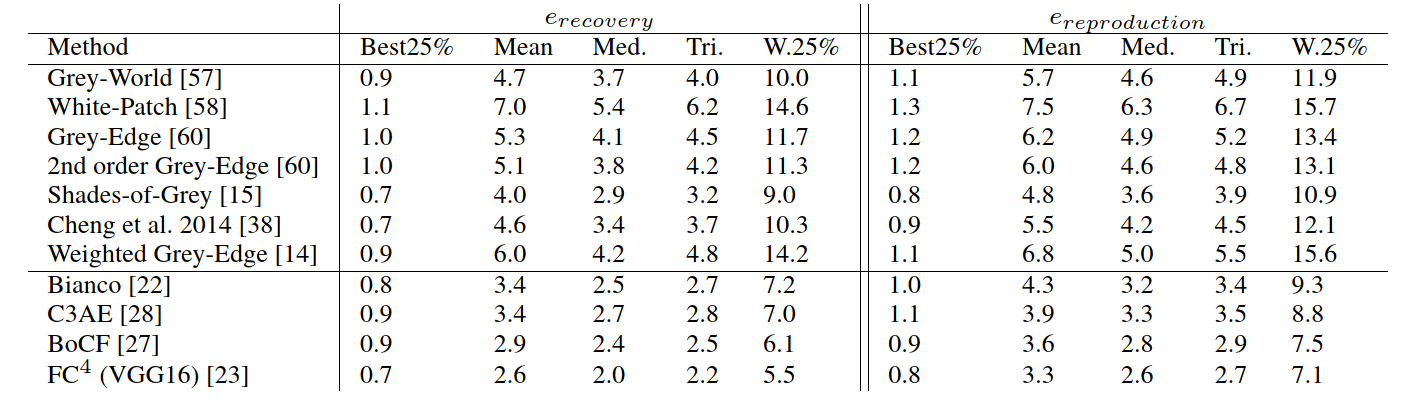
The numirical results of the different approaches on INTEL-TAU datasets. We report the different statistics of the Recovery and Reproduction errors using the 10-fold cross validation protocol.
We also provide some visual results of BoCF on three samples from INTEL-TAU. From left to right, the input image, the corrected images with BoCF method, and the ground truth image.
Cite This Work
@article{laakom2020bag,
title={Bag of color features for color constancy},
author={Laakom, Firas and Passalis, Nikolaos and Raitoharju, Jenni and Nikkanen, Jarno and Tefas, Anastasios and Iosifidis, Alexandros and Gabbouj, Moncef},
journal={IEEE Transactions on Image Processing},
volume={29},
pages={7722--7734},
year={2020},
publisher={IEEE}
}
@article{laakom2021intel,
title={Intel-tau: A color constancy dataset},
author={Laakom, Firas and Raitoharju, Jenni and Nikkanen, Jarno and Iosifidis, Alexandros and Gabbouj, Moncef},
journal={IEEE Access},
volume={9},
pages={39560--39567},
year={2021},
publisher={IEEE}
}
Note: This repository contains the course microservice of the Sumé LMS. If you are looking for more information
about the application, we strongly recommend you to check the documentation.
Sumé LMS is a modern and open-source learning management system that uses modern technologies to deliver performance
and scalability to your learning environment.
Access the project folder, and download the Go dependencies
$ go get ./...
It may take a while to download all the dependencies, then you are ready to build.
Building
There are two ways that you can use to build this microservice. The first one will build it using your own machine,
while the second one will build it using a container runtime. Also, you can build the container image to use it with
Docker or Podman, but it is up to you.
Here are the following instructions for each available option:
Local build
It should be pretty simple, once all the dependencies are download just run the following command:
$ make build
It will generate an executable file at the /bin directory inside the project folder, and probably you want to know
how to run it.
Container build
At this point, I’ll assume that you have installed and configure the container runtime (Docker or Podman) in your system.
You can have your local database running the following command:
$ docker-compose up -d postgres
And then you could run the migrations using
$ make migration-up
Note
You will have to install the golang-migrate tool
It uses the same environment variables from the configuration section.
Running
OK! Now you build it you need to run the microservice. That should also be pretty easy.
Local run
If you want to run the microservice locally, you may need to have a Postgres instance running and accessible
from your machine, and you may need to first configure it. Then you can run it, you just need to
execute the following command:
If you want to run the microservice using a container runtime, the easiest way to do it is using the docker-composer
or podman-compose.
All that you need to do is, execute the command:
$ make compose-up
It should create 2 containers, one that runs the microservice and another that runs the Postgres. If you already
have your own Postgres instance you can only run the microservice container:
$ make container-run
Keep in mind that, in both cases, it will load the config/config.yml file from the project. If you want to change some
configurations you can set the environment variables in your docker-compose.yml file, or edit the configuration file.
You can easily configure the application editing the config/config.yml file or using environment variables. We do
strongly recommend that you use the configuration file instead of the environment variables. Again, it is up to you
to decide. If you want to use the variables, be sure to prefix it all with SUMELMS_.
The list of the environment variables and it’s default values:
We are using configuro to manage the configuration, so the precedence
order to configuration is: Environment variables > .env > Config File > Value set in Struct before loading.
Testing
You can run all the tests with one single command:
$ make test
Documentation
The complete Sumé LMS documentation can be found in our official website.
API
This project uses Swagger to generate the API documentation and API mockup, the files can be
found swagger directory.
Sometimes, a microservice can cover more than one domain boundary, in this case, the API scheme should be stored in the
same directory indicated above, but following the following filename convention: <domain-name>-api.yaml
The best way to edit the API scheme is by using the Swagger Editor.
Contributing
Thank you for considering contributing to the project. In order to ensure that the Sumé LMS community is welcome to
all make sure to read our Contributor Guideline.
Code of Conduct
Would you like to contribute and participate in our communities? Please read our Code of Conduct.
The repo provides a set of tools for creating PyTorch Geometric (PyG) data objects from AnnData objects, which are commonly used for storing and manipulating single-cell genomics data. In addition, the repo includes functionality for creating PyTorch Lightning (PyTorch-Lightning) DataModule objects from the PyG data objects, which can be used to create graph neural network (GNN) data pipelines. The PyG data objects represent graphs, where the nodes represent cells and the edges represent relationships between the cells, and can be used to perform GNN tasks such as node classification, graph classification, and link prediction. The repo is written in Python and utilizes the PyTorch, PyTorch Geometric, and PyTorch-Lightning libraries.
Getting started
Please refer to the documentation. In particular, the
Alioli is a food app that aims to centralize different recipe and product functionalities in one place.
Built with Flutter and Firebase, it includes the use of design patterns, NoSQL and SQLite databases, and integration with external APIs.
Download by clicking on the following image:
📸 Screenshots
📌 Features
With Alioli you can:
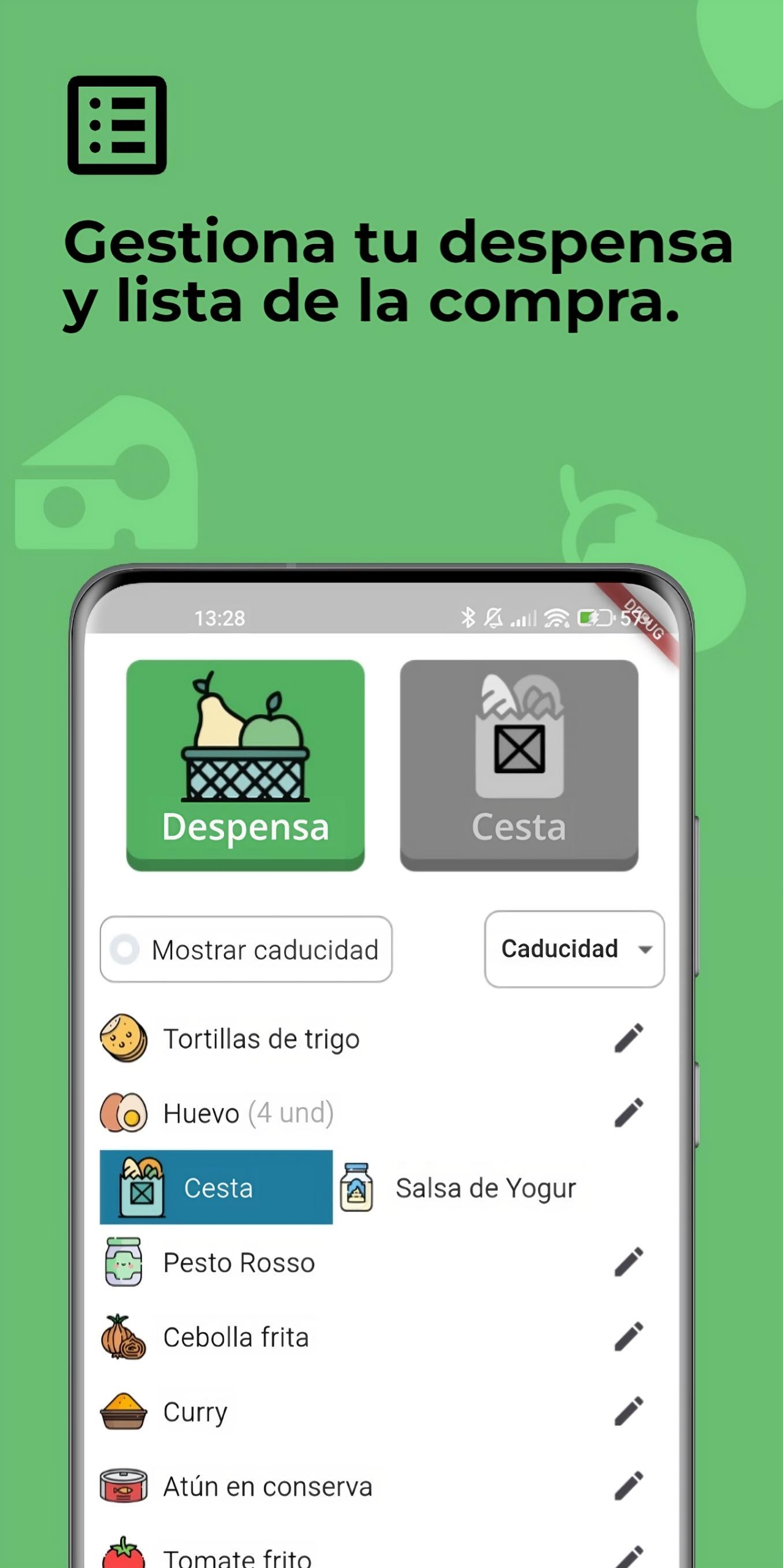
🛒 Organize your pantry food list, as well as your shopping list.
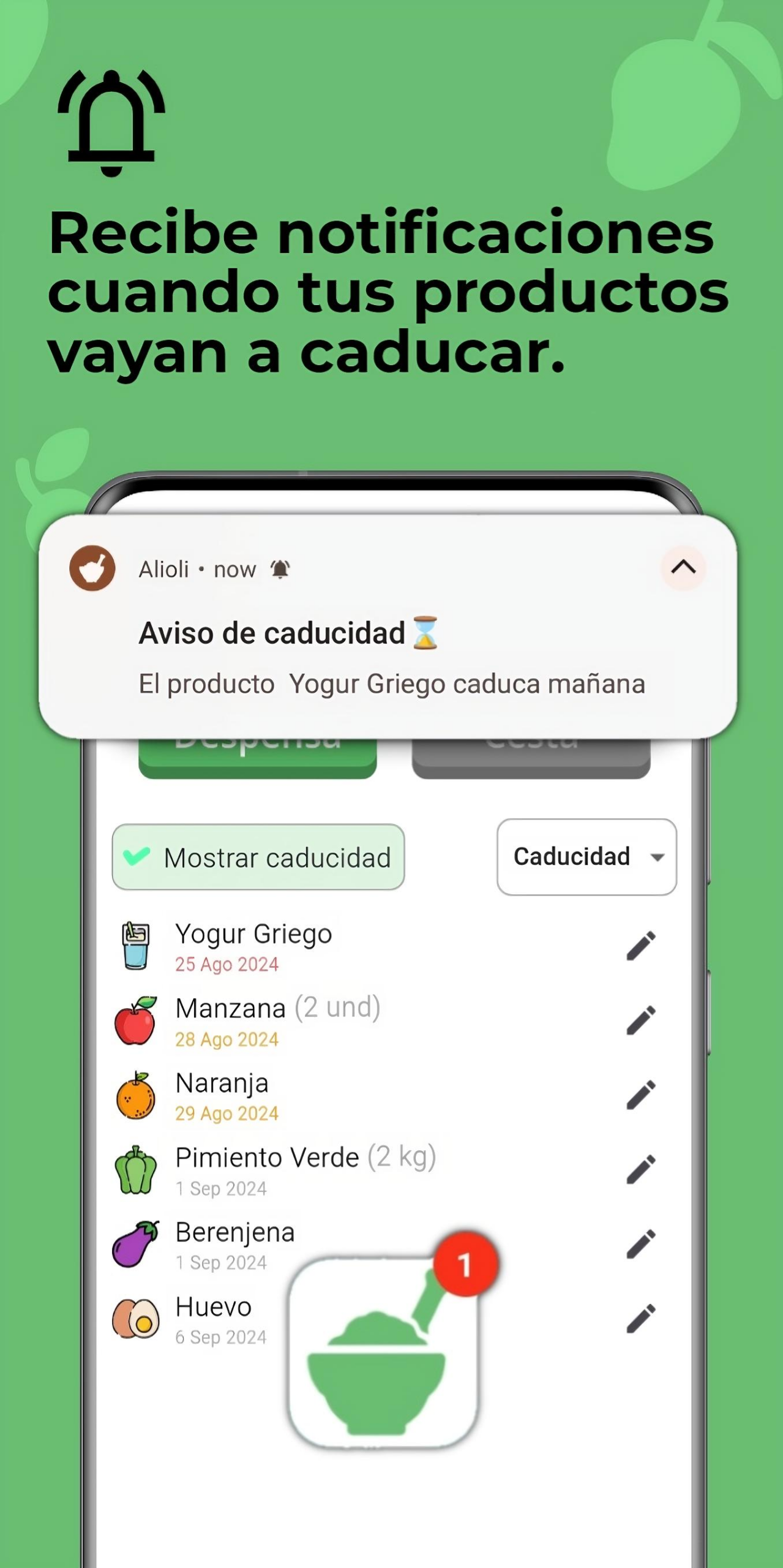
📅 Receive notifications when your products are close to their expiration date.
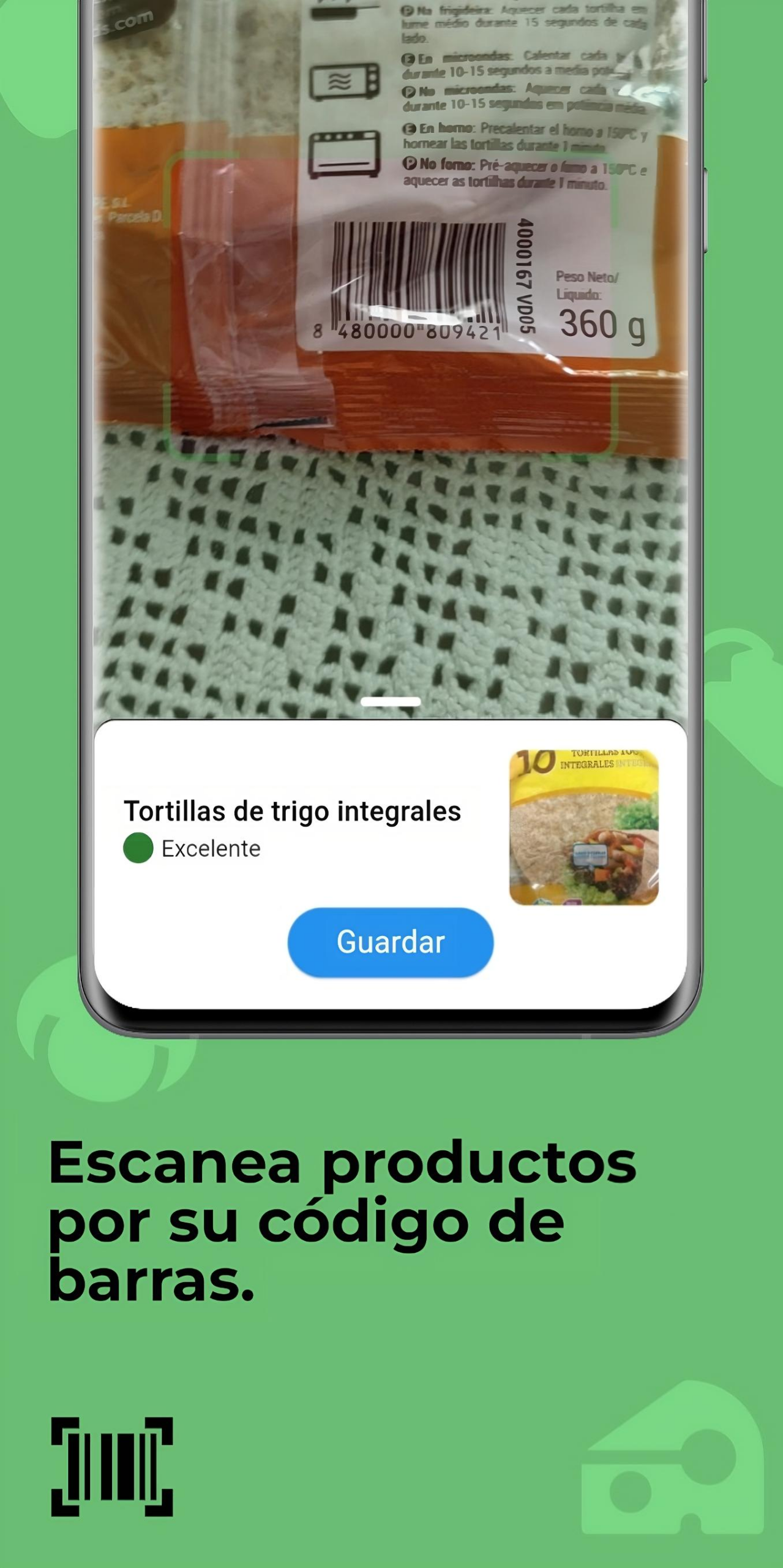
🔍 Scan the barcode of the products to get a summary of their nutritional information.
🥕 Search for recipes based on the foods in your pantry, among other search criteria such as recipe name or category to which they belong.
🔧 Apply a multitude of filters to searches, classifying them by vegan, vegetarian, preparation time, best rating or existence of videos among other filters.
📚 Create your own personalized recipe lists.
⬆️ Upload your own recipes to the platform so that they can be accessible by everyone.
Alioli – Aplicación en Flutter
Alioli es una aplicación sobre alimentación que trata de centralizar distintas funcionalidades sobre recetas y productos en un solo lugar.
Realizada con Flutter y Firebase, incluye el uso de patrones de diseño, bases de datos NoSQL y SQLite e integración con apis externas.
Descargar haciendo click sobre la siguiente imagen:
📸 Capturas
📌 Características
Con Alioli puedes:
🛒 Organizar tu lista de alimentos en despensa, así como tu lista de la compra.
📅 Recibir notificaciones cuando tus productos estén próximos a su fecha de caducidad.
🔍 Escanear el código de barras de los productos para obtener un resumen de su información nutricional.
🥕 Buscar recetas basadas en los alimentos de tu despensa, entre otros criterios de búsqueda como nombre de la receta o categoría a la que pertenecen.
🔧 Aplicar multitud de filtros a las búsquedas, clasificándolas por veganas, vegetarianas, tiempo de preparación, mejor valoración o existencia de vídeos entre otros filtros.
📚 Crear tus propias listas de recetas personalizadas.
⬆️ Subir tus propias recetas a la plataforma para que puedan ser accesibles por todo el mundo.
NOTE: The ones with * after the links are ones that are vetted. If you use your uc email and tell them your a cyber student, they wil mostly likely give you access.
The reason why ARCHFLAGS needs to be specified is due to Apple’s bugs in Xcode12.
It is recommended to explicitly specify the resolver options until pip version 20.3.
Prepare .env and .env.gpg
Write the API Key to .env and encrypt it.
Keep your passphrase in a secure location like YubiKey.